
{kind=link}
How PyTorch implements DataParallel?
PyTorch can send batches and models to different GPUs automatically with DataParallel(model). How is it possible? I assume you know PyTorch uses dynamic computational graph as well as Python GIL. And PyTorch version is v1.0.1.
This is a complicated question and I asked on the PyTorch forum. I got a reply from Sebastian Raschka.
TL;DR:
PyTorch trys hard in zero-copying. DataParallel splits tensor by its total size instead of along any axis.
DataParallel interface
Module defines its constructor and forward function. And DataParallel does the same. Let’s focus on forward.
def forward(self, *inputs, **kwargs):
# ...
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids) # Step 1, 2
# ...
self.module(*inputs[0], **kwargs[0]) # Build graph
replicas = self.replicate(self.module, self.device_ids[:len(inputs)]) # Step 3
outputs = self.parallel_apply(replicas, inputs, kwargs) # Step 4
return self.gather(outputs, self.output_device) # Step 5
There are 4 methods extracted and defined as instance methods which are scatter, replicate, gather and parallel_apply. They executes the step 1, 2; step 3; step 4; step 5 respectively.
Firstly, we have to recognize PyTorch utilize dynamic computational graph. That’s why module is invoked to build nodes. It builds the graph, parameters, grads and buffers.
And how Function works
Before we start to look into diffierent steps, let’s look at Function. We are going to see it many times.
class Function(with_metaclass(FunctionMeta, _C._FunctionBase, _ContextMethodMixin, _HookMixin)):
@staticmethod
def forward(ctx, *args, **kwargs):
r"""...
It must accept a context ctx as the first argument, followed by any
number of arguments (tensors or other types).
The context can be used to store tensors that can be then retrieved
during the backward pass.
"""
raise NotImplementedError
@staticmethod
def backward(ctx, *grad_outputs):
raise NotImplementedError
Some helper functions used Function as the base class. Moreover, since you will see Function.apply a lot in the following, we should see how it works. (metaclass is tricky.)
def with_metaclass(meta, *bases):
"""Create a base class with a metaclass."""
# This requires a bit of explanation: the basic idea is to make a dummy
# metaclass for one level of class instantiation that replaces itself with
# the actual metaclass.
class metaclass(meta):
def __new__(cls, name, this_bases, d):
return meta(name, bases, d)
return type.__new__(metaclass, 'temporary_class', (), {})
This is tricky. We have to start from Python’s object design. Starting from Python 3, everything is an object. And all objects are constructed by class type(name, bases, dict). Each parameter would become class object’s __name__, __bases__, and __dict__. So type is the dynamic way to build a class. with_metaclass is a helper to build a metaclass without defining __dict__ yet. Namely, with_metaclass(FunctionMeta, _C._FunctionBase, _ContextMethodMixin, _HookMixin)) reads FunctionMeta is the metaclass but the bases are in the tuple.
Then we are not far away from how it works.
class FunctionMeta(type):
def __init__(cls, name, bases, attrs):
// ...
backward_fn = type(name + 'Backward', (BackwardCFunction,), {'_forward_cls': cls})
setattr(cls, '_backward_cls', backward_fn)
return super(FunctionMeta, cls).__init__(name, bases, attrs)
Basically a backward_fn is defined and stored in _backward_cls. Its base class is simple.
class BackwardCFunction(_C._FunctionBase, _ContextMethodMixin, _HookMixin):
# ...
def apply(self, *args):
return self._forward_cls.backward(self, *args)
It will invoke the Function class’s backward method. Therefore _C._FunctionBase is more interesting. C._FunctionBase is defined by THPFunctionType. And the THPFunction defines its data structure.
static struct PyMethodDef THPFunction_methods[] = {
{(char*)"apply", (PyCFunction)THPFunction_apply, METH_CLASS | METH_VARARGS, nullptr},
{(char*)"_do_forward", (PyCFunction)THPFunction_do_forward, METH_VARARGS, nullptr},
{(char*)"_do_backward", (PyCFunction)THPFunction_do_backward, METH_VARARGS, nullptr},
{(char*)"_register_hook_dict", (PyCFunction)THPFunction__register_hook_dict, METH_O, nullptr},
{(char*)"register_hook", (PyCFunction)THPFunction_register_hook, METH_O, nullptr},
{nullptr}
};
It defines the apply method. That’s something we are interested.
PyObject *THPFunction_apply(PyObject *cls, PyObject *inputs)
{
// ...
THPObjectPtr backward_cls(PyObject_GetAttrString(cls, "_backward_cls"));
if (!backward_cls) return nullptr;
THPObjectPtr ctx_obj(PyObject_CallFunctionObjArgs(backward_cls, nullptr));
if (!ctx_obj) return nullptr;
THPFunction* ctx = (THPFunction*)ctx_obj.get();
// Prepare inputs and allocate context (grad fn)
auto info_pair = unpack_input<false>(inputs);
UnpackedInput& unpacked_input = info_pair.first;
InputFlags& input_info = info_pair.second;
// Record input nodes if tracing
// ...
// Initialize backward function (and ctx)
bool is_executable = input_info.is_executable;
ctx->cdata.set_next_edges(std::move(input_info.next_edges));
ctx->needs_input_grad = input_info.needs_input_grad.release();
ctx->is_variable_input = std::move(input_info.is_variable_input);
// Prepend ctx to input_tuple, in preparation for static method call
auto num_args = PyTuple_GET_SIZE(inputs);
THPObjectPtr ctx_input_tuple(PyTuple_New(num_args + 1));
PyTuple_SET_ITEM(ctx_input_tuple.get(), 0, ctx_obj.release());
// ...
// Call forward
THPObjectPtr tensor_outputs;
{
AutoGradMode grad_mode(false);
THPObjectPtr forward_fn(PyObject_GetAttrString(cls, "forward"));
if (!forward_fn) return nullptr;
tensor_outputs = PyObject_CallObject(forward_fn, ctx_input_tuple);
if (!tensor_outputs) return nullptr;
}
return process_outputs(cls, ctx, unpacked_input, inputs, std::move(tensor_outputs),
is_executable, node);
END_HANDLE_TH_ERRORS
}
From here, we know that the cls.apply invokes cls.forward and prepares information for cls.backward. cls.apply takes its own class information and all parameters from Python. And those parameters will be applied on cls.forward. Noticabily, ctx object can carry the information to backward pass.
Now we can explore how DataParallel works.
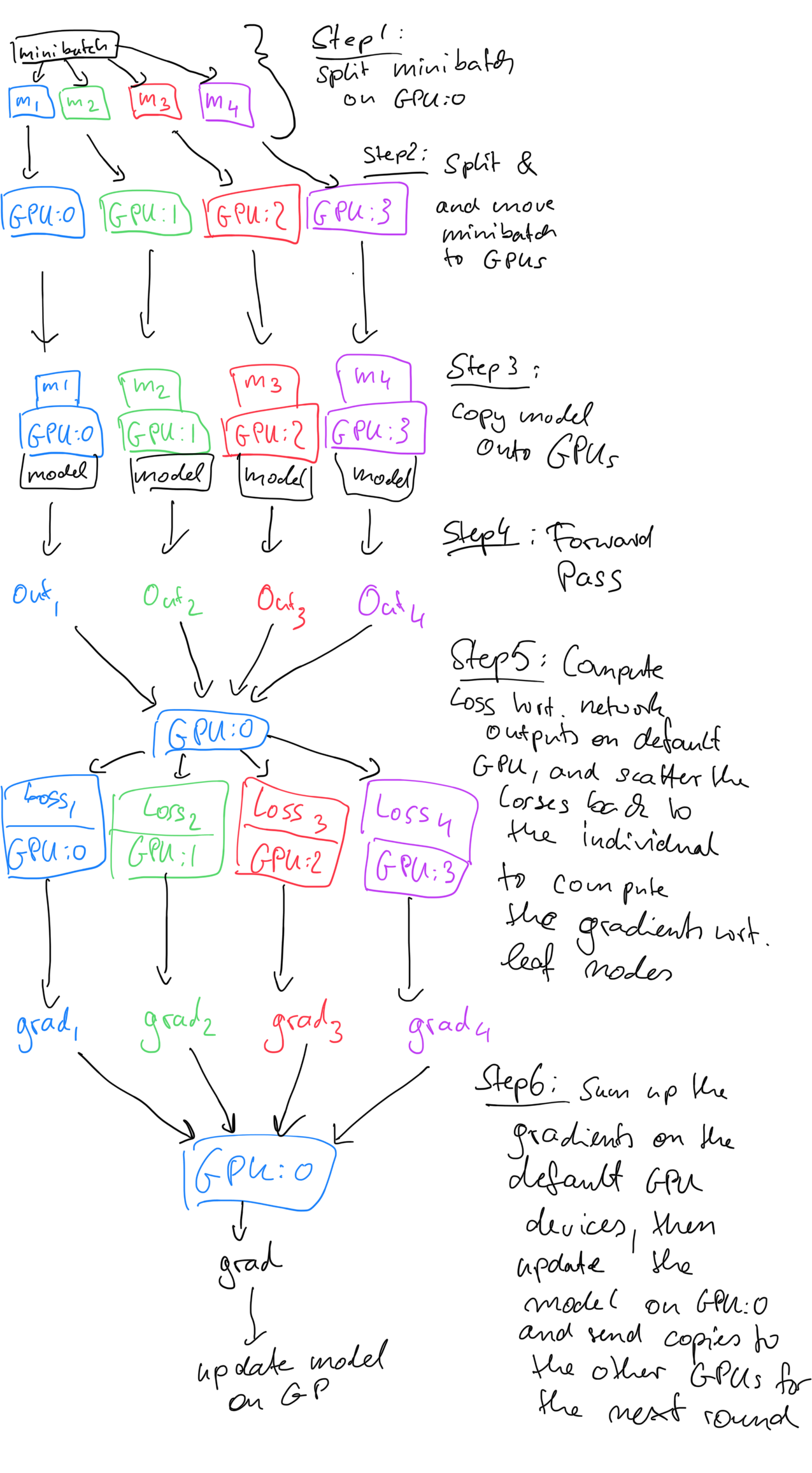
Step 1 and Step 2: split minibatch on GPU:0 and move to GPU
scatter scatters the input argugments and returns a tuple of inputs and kwargs. The actual definiton is here:
def scatter_kwargs(inputs, kwargs, target_gpus, dim=0):
r"""Scatter with support for kwargs dictionary"""
inputs = scatter(inputs, target_gpus, dim) if inputs else []
kwargs = scatter(kwargs, target_gpus, dim) if kwargs else []
# ...
return inputs, kwargs
scatter function is a recursive closure unwrap its input tensor(s). But its core is the Scatter class. This is a Function class which will operate differently in forward and backward.
class Scatter(Function):
@staticmethod
def forward(ctx, target_gpus, chunk_sizes, dim, input):
# ...
outputs = comm.scatter(input, target_gpus, chunk_sizes, ctx.dim, streams)
# Synchronize with the copy stream
if streams is not None:
for i, output in enumerate(outputs):
with torch.cuda.device(target_gpus[i]):
main_stream = torch.cuda.current_stream()
main_stream.wait_stream(streams[i])
output.record_stream(main_stream)
return outputs
@staticmethod
def backward(ctx, *grad_output):
return None, None, None, Gather.apply(ctx.input_device, ctx.dim, *grad_output)
Let’s focus on forward path. The backward path should be easier to understand. Thus on a multi-gpu environment, the input tensor will be sent to a PyTorch module for scattering and copying. This process needs synchronization.
The actual works in done by C++.
std::vector<at::Tensor> scatter(
const at::Tensor& tensor,
at::IntList devices,
const c10::optional<std::vector<int64_t>>& chunk_sizes, // optional parameter is bad
int64_t dim,
const c10::optional<std::vector<c10::optional<at::cuda::CUDAStream>>>& streams) {
std::vector<at::Tensor> chunks;
if (chunk_sizes) {
// ...
// flatten tensor by size. The default uses the other path
int64_t chunk_start = 0;
for (size_t chunk = 0; chunk < chunk_sizes->size(); ++chunk) {
const int64_t chunk_size = (*chunk_sizes)[chunk];
AT_CHECK(chunk_size > 0, "Chunk size must be positive");
chunks.push_back(tensor.narrow(dim, chunk_start, chunk_size));
chunk_start += chunk_size;
}
} else {
// usually a tensor is seperated into chunks among devices
chunks = tensor.chunk(/*chunks=*/devices.size(), /*dim=*/dim);
}
at::cuda::OptionalCUDAStreamGuard cuda_guard;
for (size_t chunk = 0; chunk < chunks.size(); ++chunk) {
// ...
// dispatch to different devices
chunks[chunk] = chunks[chunk].contiguous().to(
{at::DeviceType::CUDA, device_index}, /*non_blocking=*/true);
}
return chunks;
}
As a matter of fact, tensor would be split which is done by at::narrow in the end. Since the operation only happens to strides and sizes, the memory is reused! PyTorch takes zero copy seriously at every level. But an important insight is that tensor is splitted regardless of its shape. You need to align different input tensors by its total size instead of a particular dimension.
Step 3: copy models to GPU
replicate sounds easy! But no. So the module is passed in as network.
def replicate(network, devices, detach=False):
from ._functions import Broadcast
// ...
num_replicas = len(devices)
// copy model parameters
params = list(network.parameters())
param_indices = {param: idx for idx, param in enumerate(params)}
param_copies = Broadcast.apply(devices, *params)
if len(params) > 0:
param_copies = [param_copies[i:i + len(params)]
for i in range(0, len(param_copies), len(params))]
// copy model buffers
buffers = list(network.buffers())
buffer_indices = {buf: idx for idx, buf in enumerate(buffers)}
buffer_copies = comm.broadcast_coalesced(buffers, devices)
// copy model modules
modules = list(network.modules())
module_copies = [[] for device in devices]
module_indices = {}
// construrct modules
// ...
// copy every submodules
for i, module in enumerate(modules):
for key, child in module._modules.items():
// ...
replica = module_copies[j][i]
replica._modules[key] = module_copies[j][module_idx]
// and their parameters
for key, param in module._parameters.items():
// ...
replica = module_copies[j][i]
replica._parameters[key] = param_copies[j][param_idx].detach() \
if detach else param_copies[j][param_idx]
// also buffers
for key, buf in module._buffers.items():
// ...
replica = module_copies[j][i]
replica._buffers[key] = buffer_copies[j][buffer_idx]
return [module_copies[j][0] for j in range(num_replicas)]
The copying part to GPU is hard to be found. But we know they are Broadcast and comm.broadcast_coalesced(buffers, devices).
Until this point, we have the model living in different GPUs.
Here is the Broadcast. The invocation starts with Broadcast.apply(devices, *params).
class Broadcast(Function):
@staticmethod
def forward(ctx, target_gpus, *inputs):
// ...
ctx.target_gpus = target_gpus
if len(inputs) == 0:
return tuple()
ctx.num_inputs = len(inputs)
ctx.input_device = inputs[0].get_device()
outputs = comm.broadcast_coalesced(inputs, ctx.target_gpus)
// ...
return tuple([t for tensors in outputs for t in tensors])
@staticmethod
def backward(ctx, *grad_outputs):
return (None,) + ReduceAddCoalesced.apply(ctx.input_device, ctx.num_inputs, *grad_outputs)
And its backward direction ReduceAddCoalesced looks similar.
class ReduceAddCoalesced(Function):
@staticmethod
def forward(ctx, destination, num_inputs, *grads):
// ...
grads = [grads[i:i + num_inputs]
for i in range(0, len(grads), num_inputs)]
return comm.reduce_add_coalesced(grads, destination)
@staticmethod
def backward(ctx, *grad_outputs):
return (None, None,) + Broadcast.apply(ctx.target_gpus, *grad_outputs)
So the core parts are comm.broadcast_coalesced and comm.reduce_add_coalesced.
The comm.broadcast_coalesced is implemented in C++. We have model parameters as tensors.
tensor_list2d broadcast_coalesced(TensorList tensors, IntArrayRef devices, size_t buffer_size) {
if (!std::all_of(tensors.begin(), tensors.end(),
[&](const at::Tensor& t) { return t.get_device() == devices[0]; })) {
throw std::runtime_error("all tensors must be on devices[0]");
}
// ...
tensor_list2d outputs(devices.size());
outputs[0] = tensors.vec();
// ...
for (auto & chunk : utils::take_tensors(tensors, buffer_size)) {
// ...
std::vector<at::Tensor> results;
if (chunk.type().is_sparse()) {
auto flat_tuple = utils::flatten_sparse_tensors(chunk.tensors);
std::vector<at::Tensor> broadcast_indices = broadcast(flat_tuple.first, devices);
std::vector<at::Tensor> broadcast_values = broadcast(flat_tuple.second, devices);
// ...
} else {
std::vector<Tensor> results = broadcast(utils::flatten_dense_tensors(chunk.tensors),
devices);
// ...
}
}
// ...
return outputs;
}
This is too complicated and perhaps not insightful for our aim. But effecitively NCCL is used to broadcast tensor’s address to multiple GPUs. reduce_add_coalesced does the reverse.
Step 4: Forward pass
Finally, this step is obvious. But we need to pay attention to the output tuple because of the next step.
def parallel_apply(modules, inputs, kwargs_tup=None, devices=None):
r"""Applies each `module` in :attr:`modules` in parallel on arguments
contained in :attr:`inputs` (positional) and :attr:`kwargs_tup` (keyword)
on each of :attr:`devices`.
Args:
modules (Module): modules to be parallelized
inputs (tensor): inputs to the modules
devices (list of int or torch.device): CUDA devices
:attr:`modules`, :attr:`inputs`, :attr:`kwargs_tup` (if given), and
:attr:`devices` (if given) should all have same length. Moreover, each
element of :attr:`inputs` can either be a single object as the only argument
to a module, or a collection of positional arguments.
"""
# ...
def _worker(i, module, input, kwargs, device=None):
# ...
try:
with torch.cuda.device(device):
# this also avoids accidental slicing of `input` if it is a Tensor
if not isinstance(input, (list, tuple)):
input = (input,)
output = module(*input, **kwargs)
with lock:
results[i] = output
except Exception as e:
with lock:
results[i] = e
if len(modules) > 1:
threads = [threading.Thread(target=_worker,
args=(i, module, input, kwargs, device))
for i, (module, input, kwargs, device) in
enumerate(zip(modules, inputs, kwargs_tup, devices))]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
else:
_worker(0, modules[0], inputs[0], kwargs_tup[0], devices[0])
# ...
return outputs
results keeps track of results from every devices. Most cases, it will be a scalar loss tensor.
Python’s threading library is used to send things to models on different GPUs. This is a little bit expensive than I thought because of the overhead from threading.
Step 5: Compute
The gather has a similiar design as scatter. The core is Gather.apply(target_device, dim, *outputs). And its core is comm.gather(inputs, ctx.dim, ctx.target_device).
at::Tensor gather(
at::TensorList tensors,
int64_t dim,
c10::optional<int32_t> destination_index) {
# ...
AT_CHECK(!tensors.empty(), "Expected at least one tensor to gather from");
at::Tensor result;
int64_t total_size = 0;
auto& first = tensors.front();
const auto first_size = first.sizes();
std::vector<int64_t> expected_size(first_size.begin(), first_size.end());
for (const auto& tensor : tensors) {
// ...
expected_size[dim] = tensor.size(dim);
// ...
total_size += tensor.size(dim);
}
expected_size[dim] = total_size;
at::Device device(at::DeviceType::CPU);
if (!destination_index || *destination_index != -1) {
device = at::Device(at::DeviceType::CUDA, destination_index ? *destination_index : -1);
}
result = at::empty(expected_size, first.options().device(device));
int64_t chunk_start = 0;
for (const auto& tensor : tensors) {
result.narrow(dim, chunk_start, tensor.size(dim))
.copy_(tensor, /*non_blocking=*/true);
chunk_start += tensor.size(dim);
}
return result;
}
It’s actually hard to find things. This basically compose a final tensor from tensors from devices. destination_index is the index of output device which is GPU:0 by default (defined as the parameter of data_parrallel).
Step 6: Loss value
This is the standard code you will write.
loss = model.forward(x)
loss = loss.sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
In next minibatch, same process will be sent to GPU.
Discussion
PyTorch focuses on abstraction and zero-copy. It’s more intutive to Tensorflow 1.x. It’s indeed an engineering success. Despite its simple interfaces, we need to understand its Tensor abstraction and those convenient helpers. Since CUDA uses different programming models, the work to hide CUDA details is enormous. PyTorch did this by mixing C++ and Python with pybind11. And it strives to maintain a similiar language in a large hierarchy that aligns the Tensor, Function, and Model. That’s remarkable.
Though, programming in a mixed languages are difficult. Type checking is always complicated. GIL needs to be remembered. With CUDA, synchronization, memory management and communication expands the scope of engineering work.
Share on
X Facebook LinkedIn BlueskyComments are configured with provider: disqus, but are disabled in non-production environments.